350 lines
7.1 KiB
Markdown
350 lines
7.1 KiB
Markdown
|
|
---
|
|||
|
|
title: 【大数据】Ubuntu 18.04.6 下部署 hadoop 2.7.1 集群
|
|||
|
|
date: 2024/3/6 20:30
|
|||
|
|
tags: [ubuntu, hadoop, vmware, linux]
|
|||
|
|
categories: 技术
|
|||
|
|
permalink: 377.html
|
|||
|
|
index_img: https://i.dawnlab.me/94e2f67b3a97d256229d9a1466c0206e.png
|
|||
|
|
---
|
|||
|
|
|
|||
|
|
# 前言
|
|||
|
|
|
|||
|
|
本文安装的 Hadoop 2.7.1 基于 Java 1.8.0_25 ,虚拟机 NAT 网络为 192.168.88.0/24
|
|||
|
|
|
|||
|
|
## 主要步骤
|
|||
|
|
|
|||
|
|
- 安装 Ubuntu 图形化界面并且配置静态 IP
|
|||
|
|
- 创建 Hadoop 用户
|
|||
|
|
- 更新 apt 以及 安装必要软件
|
|||
|
|
- 使用 SSH 软件连接虚拟机
|
|||
|
|
- 安装 Java
|
|||
|
|
- 安装 Hadoop
|
|||
|
|
- 配置其他主机
|
|||
|
|
- 启动集群
|
|||
|
|
|
|||
|
|
## 安装 Ubuntu
|
|||
|
|
|
|||
|
|
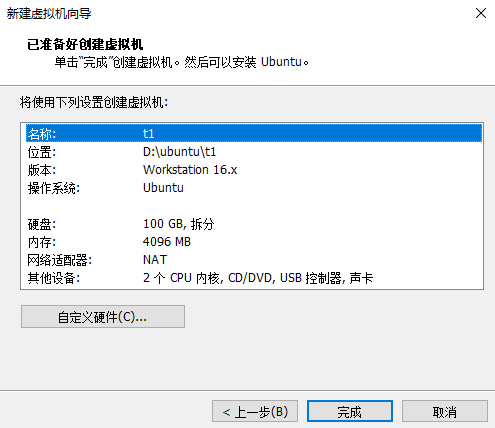
使用 vmware 新建虚拟机,100G 硬盘。
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
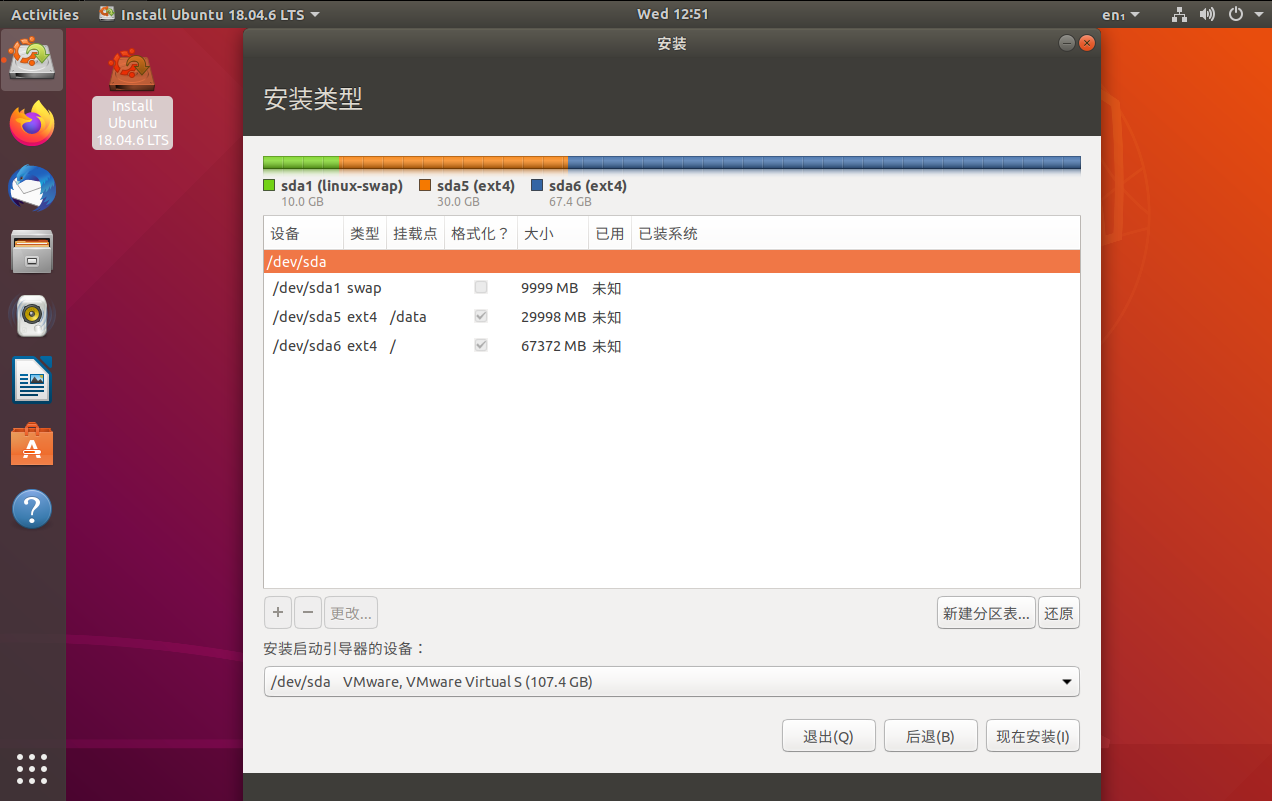
在安装阶段,分配 10G swap ,30G /data,其余分配到根目录 /
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
### 配置静态 IP
|
|||
|
|
|
|||
|
|
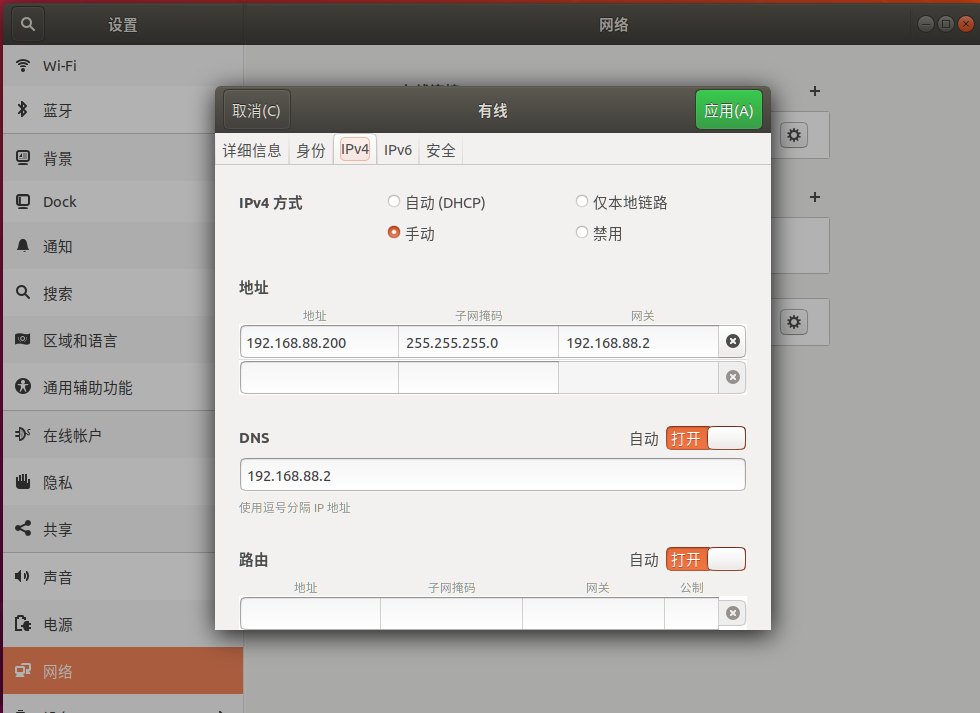
VM 网络为 192.168.88.0/24,配置 1 号机 IP 为 192.168.88.200 ,子网掩码为 255.255.255.0 ,网关 IP 为 192.168.88.2,DNS 为 192.168.88.2
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
#### 解决网络速率只有 10M
|
|||
|
|
|
|||
|
|
##### 原因
|
|||
|
|
|
|||
|
|
在选择客户机操作系统时没有选择 ubuntu 64位 而是选择了 ubuntu 这个选项,导致 Vmware默认安装的虚拟适配器是 AMD 79c970。
|
|||
|
|
|
|||
|
|
##### 解决
|
|||
|
|
|
|||
|
|
因此我们需要在选择 虚拟机设置 > 选项 > 常规 > 客户机操作系统 > 版本 > ubuntu 64位
|
|||
|
|
|
|||
|
|
同时,还需要修改该虚拟机的 .vmx文件,打开并在其末尾追加:
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
ethernet0.virtualDev = "e1000"
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
## 创建 Hadoop 用户
|
|||
|
|
|
|||
|
|
在安装时我已经创建 hadoop 用户,所以跳过此节
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
sudo useradd -m hadoop -s /bin/bash
|
|||
|
|
sudo passwd hadoop
|
|||
|
|
sudo adduser hadoop sudo
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
## 更新 apt 以及 安装必要软件
|
|||
|
|
|
|||
|
|
### 替换为清华源
|
|||
|
|
|
|||
|
|
https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu/
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
sudo mv /etc/apt/sources.list /etc/apt/sources.list.bak
|
|||
|
|
sudo nano /etc/apt/sources.list
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 安装必要软件
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
sudo apt update
|
|||
|
|
sudo apt install open-vm-tools-desktop net-tools -y
|
|||
|
|
sudo apt install openssh-server openssh-client -y
|
|||
|
|
sudo apt install lrzsz -y
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
## 使用 SSH 软件连接虚拟机
|
|||
|
|
|
|||
|
|
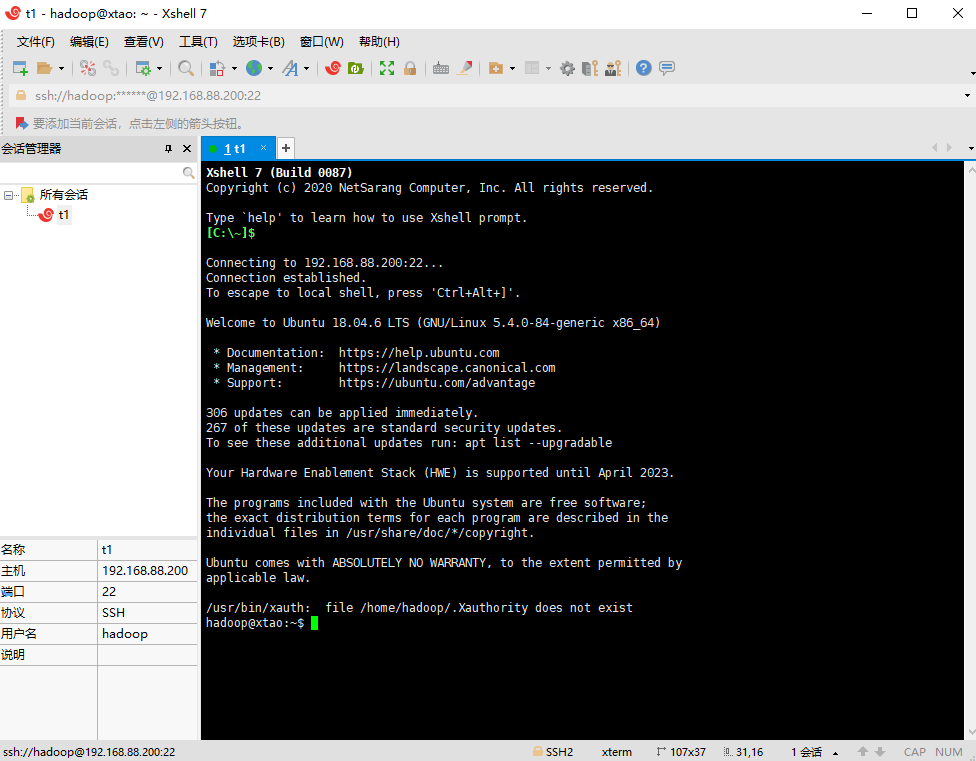
本文以 Xshell 7 为例
|
|||
|
|
|
|||
|
|
|
|||
|
|
|
|||
|
|
## 安装 Java
|
|||
|
|
|
|||
|
|
### 新建资源目录
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
sudo chown -R hadoop:hadoop /opt
|
|||
|
|
mkdir /opt/softwares
|
|||
|
|
mkdir /opt/modules
|
|||
|
|
cd /opt/softwares
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 上传文件
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
rz
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 解压
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
tar -zxvf /opt/softwares/jdk-8u25-linux-x64.tar.gz -C /opt/modules/
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 配置环境变量
|
|||
|
|
|
|||
|
|
添加以下两行到 `/etc/profile`
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
export JAVA_HOME=/opt/modules/jdk1.8.0_25
|
|||
|
|
export PATH=$PATH:$JAVA_HOME/bin
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
重新加载环境变量
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
source /etc/profile
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
## 安装 hadoop
|
|||
|
|
|
|||
|
|
### 上传文件
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
rz
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 解压
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
tar -zxvf /opt/softwares/hadoop-2.7.1.tar.gz -C /opt/modules/
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 配置环境变量
|
|||
|
|
|
|||
|
|
添加以下两行到 `/etc/profile`
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
export HADOOP_HOME=/opt/modules/hadoop-2.7.1
|
|||
|
|
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
重新加载环境变量
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
source /etc/profile
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 在 sh 脚本中加入 JAVA_HOME 变量
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
echo "export JAVA_HOME=/opt/modules/jdk1.8.0_25" >> /opt/modules/hadoop-2.7.1/etc/hadoop/hadoop-env.sh
|
|||
|
|
echo "export JAVA_HOME=/opt/modules/jdk1.8.0_25" >> /opt/modules/hadoop-2.7.1/etc/hadoop/mapred-env.sh
|
|||
|
|
echo "export JAVA_HOME=/opt/modules/jdk1.8.0_25" >> /opt/modules/hadoop-2.7.1/etc/hadoop/yarn-env.sh
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 配置 hadoop
|
|||
|
|
|
|||
|
|
#### core-site
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
cd /opt/modules/hadoop-2.7.1/etc/hadoop
|
|||
|
|
nano core-site.xml
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
修改成以下格式,其中 t1 为你自己的主机名
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
<configuration>
|
|||
|
|
<property>
|
|||
|
|
<name>fs.defaultFS</name>
|
|||
|
|
<value>hdfs://t1:9000</value>
|
|||
|
|
</property>
|
|||
|
|
<property>
|
|||
|
|
<name>hadoop.tmp.dir</name>
|
|||
|
|
<value>file:/opt/modules/hadoop-2.7.1/tmp</value>
|
|||
|
|
</property>
|
|||
|
|
</configuration>
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### hdfs-site
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
cd /opt/modules/hadoop-2.7.1/etc/hadoop
|
|||
|
|
nano hdfs-site.xml
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
<configuration>
|
|||
|
|
<property>
|
|||
|
|
<name>dfs.replication</name>
|
|||
|
|
<value>3</value>
|
|||
|
|
</property>
|
|||
|
|
<property>
|
|||
|
|
<name>dfs.namenode.name.dir</name>
|
|||
|
|
<value>file:/opt/modules/hadoop-2.7.1/tmp/dfs/name</value>
|
|||
|
|
</property>
|
|||
|
|
<property>
|
|||
|
|
<name>dfs.datanode.data.dir</name>
|
|||
|
|
<value>file:/opt/modules/hadoop-2.7.1/tmp/dfs/data</value>
|
|||
|
|
</property>
|
|||
|
|
</configuration>
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### mapred-site
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
cd /opt/modules/hadoop-2.7.1/etc/hadoop
|
|||
|
|
mv mapred-site.xml.template mapred-site.xml
|
|||
|
|
nano mapred-site.xml
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
<configuration>
|
|||
|
|
<property>
|
|||
|
|
<name>mapreduce.framework.name</name>
|
|||
|
|
<value>yarn</value>
|
|||
|
|
</property>
|
|||
|
|
</configuration>
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### yarn-site
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
cd /opt/modules/hadoop-2.7.1/etc/hadoop
|
|||
|
|
nano yarn-site.xml
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
修改成以下格式,其中 t1 为你自己的主机名
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
<configuration>
|
|||
|
|
<property>
|
|||
|
|
<name>yarn.nodemanager.disk-health-checker.min-healthy-disks</name>
|
|||
|
|
<value>0.0</value>
|
|||
|
|
</property>
|
|||
|
|
<property>
|
|||
|
|
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
|
|||
|
|
<value>100.0</value>
|
|||
|
|
</property>
|
|||
|
|
<property>
|
|||
|
|
<name>yarn.nodemanager.aux-services</name>
|
|||
|
|
<value>mapreduce_shuffle</value>
|
|||
|
|
</property>
|
|||
|
|
<property>
|
|||
|
|
<name>yarn.resourcemanager.hostname</name>
|
|||
|
|
<value>t1</value>
|
|||
|
|
</property>
|
|||
|
|
</configuration>
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### slaves
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
cd /opt/modules/hadoop-2.7.1/etc/hadoop
|
|||
|
|
nano slaves
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
修改成以下格式,其中 t1、t2、t3 为你集群的所有主机名
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
t1
|
|||
|
|
t2
|
|||
|
|
t3
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
## 配置其他主机
|
|||
|
|
|
|||
|
|
### 修改 hosts 文件
|
|||
|
|
|
|||
|
|
修改 `/etc/hosts` ,添加其他主机的映射
|
|||
|
|
|
|||
|
|
```
|
|||
|
|
192.168.88.200 t1
|
|||
|
|
192.168.88.201 t2
|
|||
|
|
192.168.88.202 t3
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 关闭虚拟机并且克隆为 t2 t3
|
|||
|
|
|
|||
|
|
vmware 中右键虚拟机,管理 -> 克隆 -> 创建完整克隆
|
|||
|
|
|
|||
|
|
### 修改对应主机的 hostname
|
|||
|
|
|
|||
|
|
修改 `/etc/hostname` ,修改主机名称为 `t1`、`t2`、`t3`
|
|||
|
|
|
|||
|
|
### 配置对应主机的静态 IP
|
|||
|
|
|
|||
|
|
如前文,另外两台主机 IP 分别为 `192.168.88.201`、`192.168.88.202`
|
|||
|
|
|
|||
|
|
重启网卡后生效
|
|||
|
|
|
|||
|
|
### 配置三台主机间的免密登录
|
|||
|
|
|
|||
|
|
在 t1 上的 hadoop 用户下操作:
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
ssh-keygen -t rsa (连续三次回车)
|
|||
|
|
ssh-copy-id t1 (如果需要输入密码就输入hadoop用户的密码)
|
|||
|
|
ssh-copy-id t2 (如果需要输入密码就输入hadoop用户的密码)
|
|||
|
|
ssh-copy-id t3 (如果需要输入密码就输入hadoop用户的密码)
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
以上命令做好后。t1 就可以免密登录 t2, t3 了,同理配置 t2, t3。
|
|||
|
|
|
|||
|
|
## 启动集群
|
|||
|
|
|
|||
|
|
### 格式化集群
|
|||
|
|
|
|||
|
|
在 t1 上的 hadoop 用户下操作:
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
hadoop namenode -format
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 启动集群
|
|||
|
|
|
|||
|
|
在 t1 上的 hadoop 用户下操作:(只能在 t1 上运行,切记不要在另外两台运行)
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
start-all.sh
|
|||
|
|
```
|
|||
|
|
|
|||
|
|
### 在宿主机上查看集群
|
|||
|
|
|
|||
|
|
http://192.168.88.200:50070
|
|||
|
|
|
|||
|
|
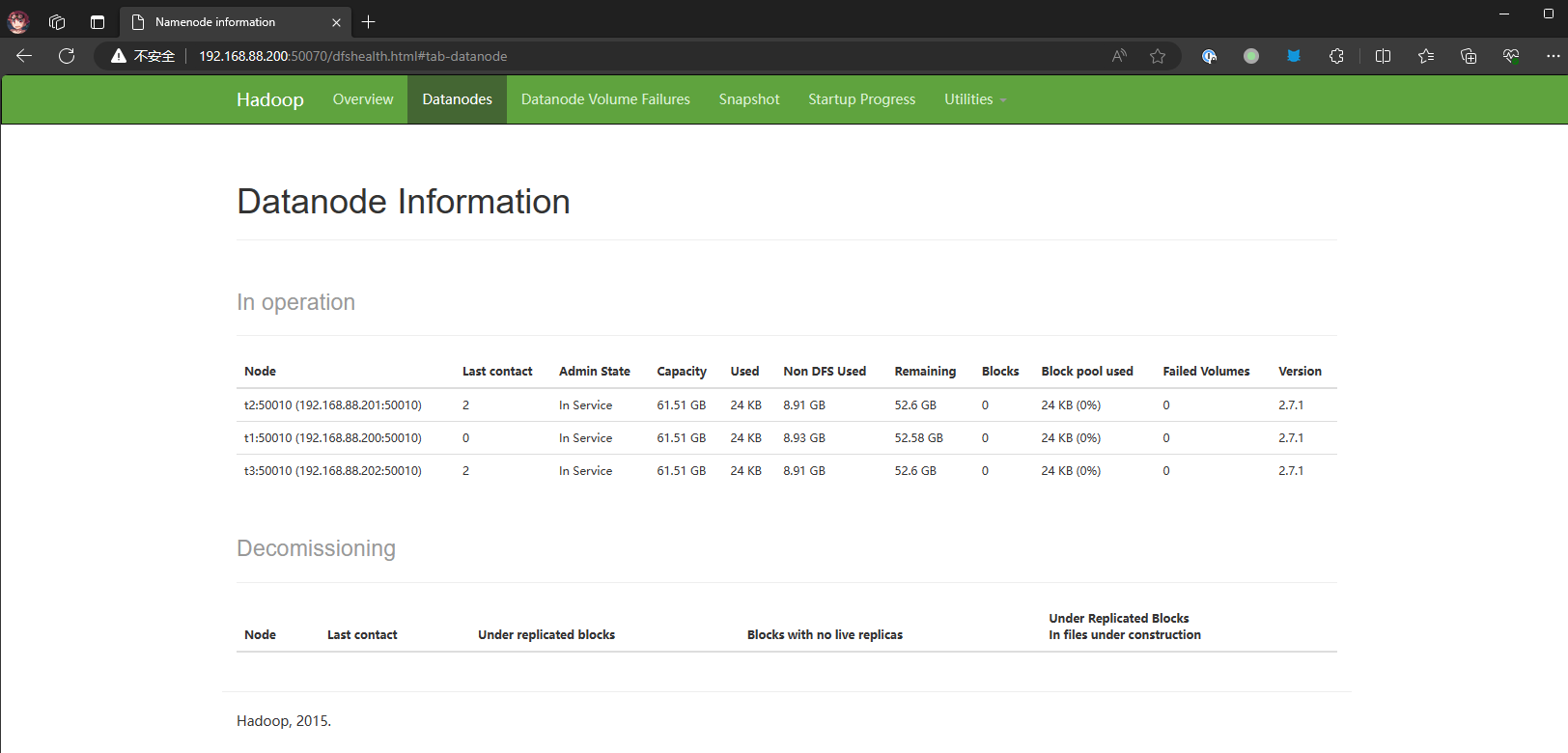
|
|||
|
|
|
|||
|
|
http://192.168.88.200:8088
|
|||
|
|
|
|||
|
|
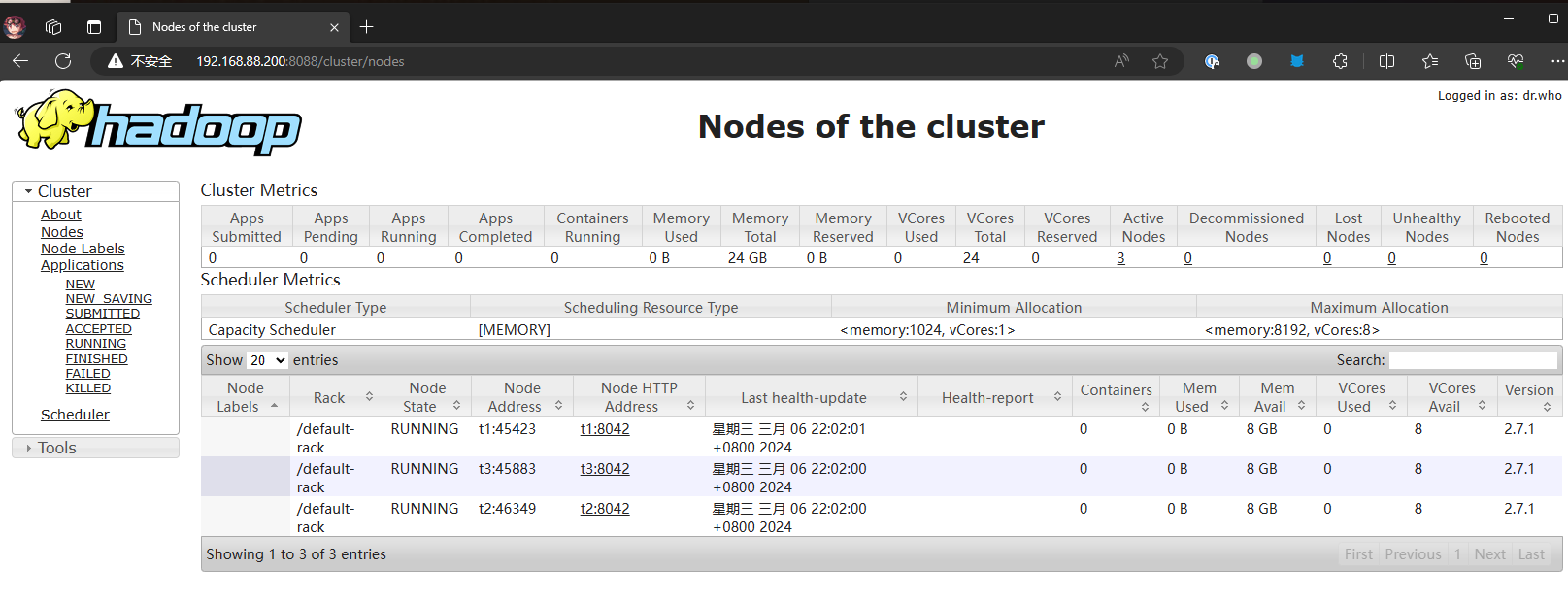
|
|||
|
|
|
|||
|
|
### 停止集群
|
|||
|
|
|
|||
|
|
```bash
|
|||
|
|
stop-all.sh
|
|||
|
|
```
|